Slide 1 of 17
Slide 1 - Attention Is All You Need
Attention Is All You Need
Introducing the Transformer: A Novel Neural Network Architecture for Sequence Transduction
---
Photo by Mirella Callage on Unsplash

Generated from prompt:
Please make a presentation from the attached paper
This presentation dives into the Transformer model from the landmark paper 'Attention Is All You Need'. It covers background on RNN/CNN limitations, the encoder-decoder architecture with self-attention, multi-head attention, positional encoding,训练细节,
Attention Is All You Need
Introducing the Transformer: A Novel Neural Network Architecture for Sequence Transduction
---
Photo by Mirella Callage on Unsplash
---
Photo by Teemu Paananen on Unsplash

1
Limitations of Recurrent and Convolutional Models in Sequence Transduction
---
Photo by Conny Schneider on Unsplash


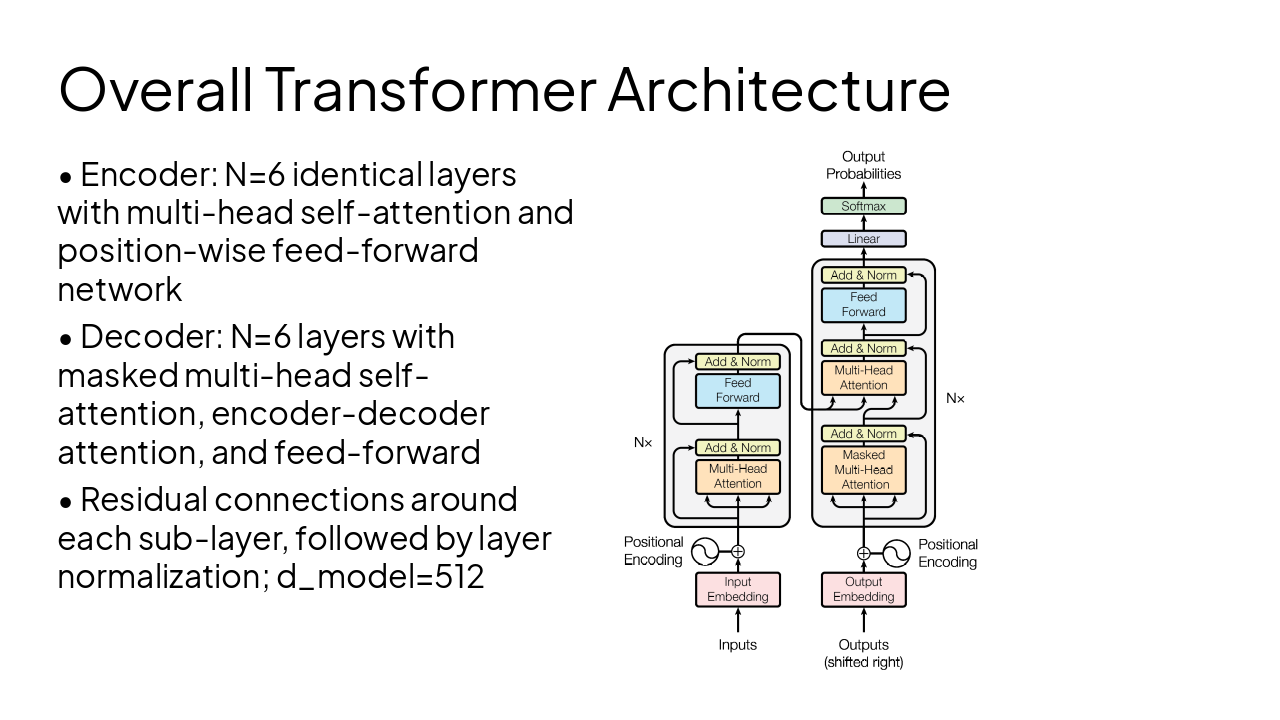

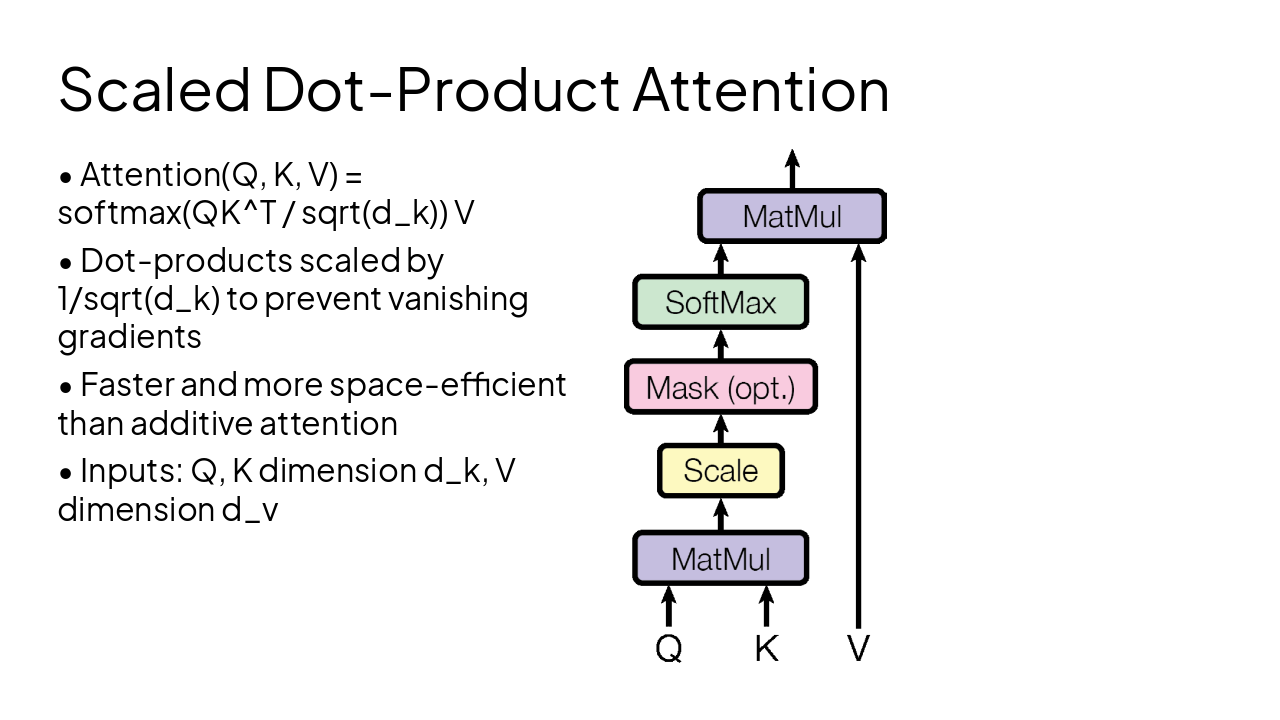
3
Scaled Dot-Product and Multi-Head Attention
---
Photo by Shane Rounce on Unsplash

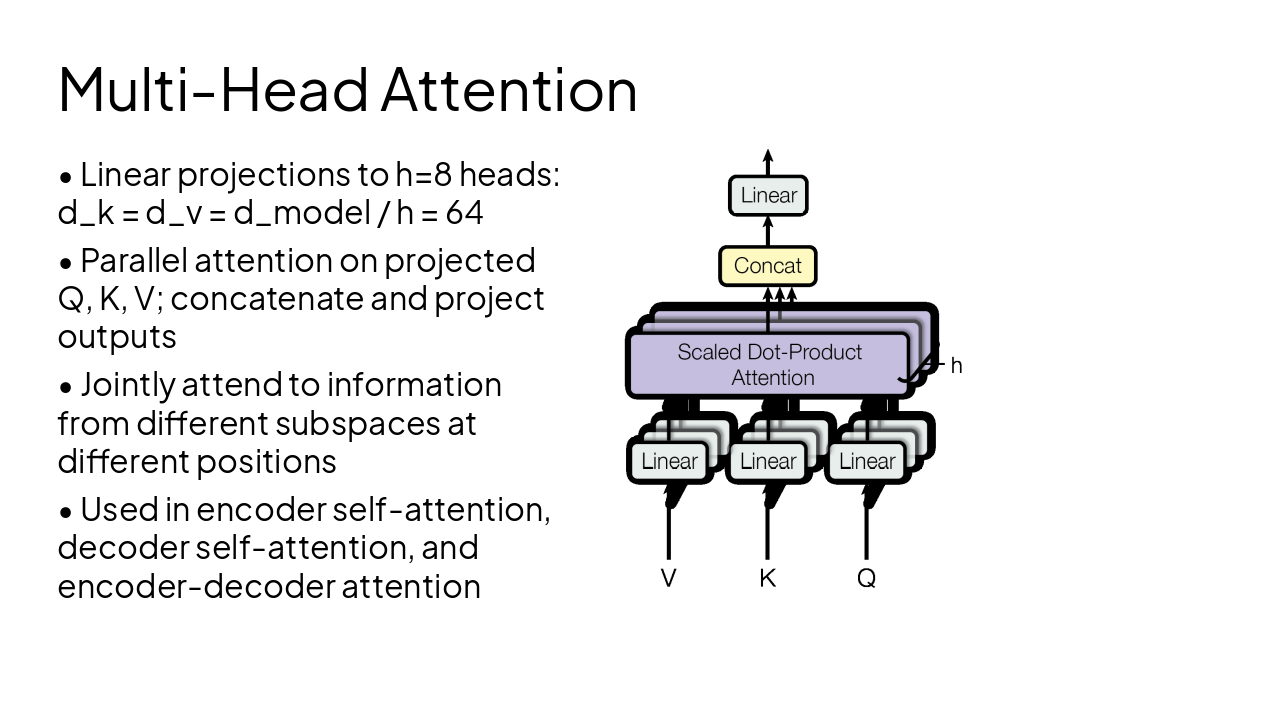

4
State-of-the-Art Performance on Machine Translation
---
Photo by Deng Xiang on Unsplash

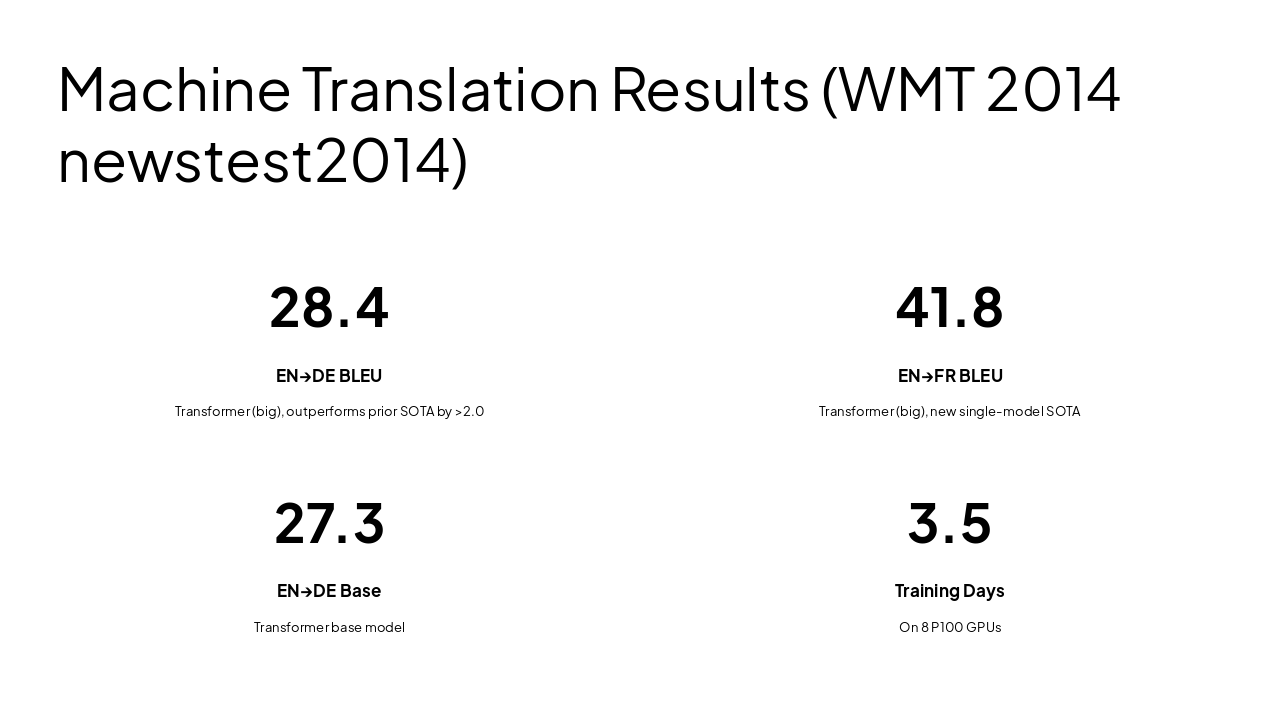
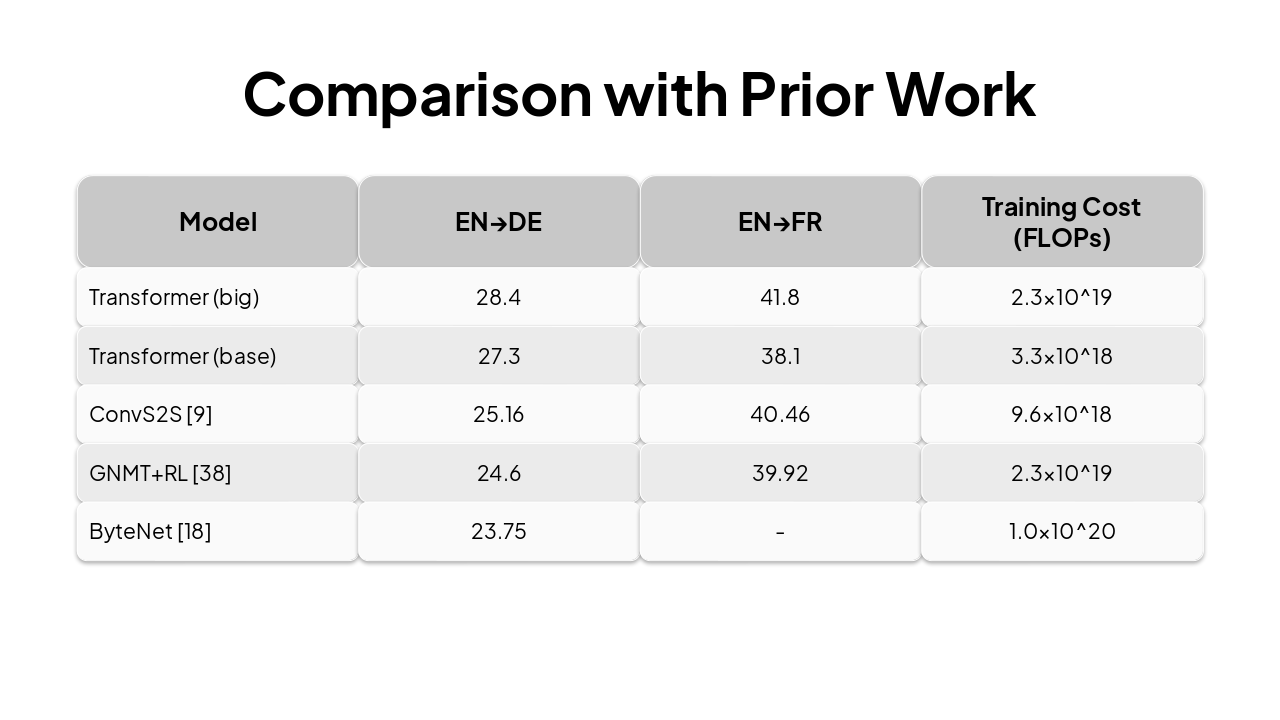
| Model | EN→DE | EN→FR | Training Cost (FLOPs) |
|---|---|---|---|
| Transformer (big) | 28.4 | 41.8 | 2.3×10^19 |
| Transformer (base) | 27.3 | 38.1 | 3.3×10^18 |
| ConvS2S [9] | 25.16 | 40.46 | 9.6×10^18 |
| GNMT+RL [38] | 24.6 | 39.92 | 2.3×10^19 |
| ByteNet [18] | 23.75 | - | 1.0×10^20 |

> We propose a new simple network architecture, the Transformer, based solely on attention mechanisms, dispensing with recurrence and convolutions entirely.
— Vaswani et al., 2017

Transformer: First transduction model relying entirely on self-attention Achieves new SOTA on translation tasks with faster training Generalizes to parsing; foundation for modern LLMs, ViTs, and more
Future: Extend to images, audio, video; less sequential generation https://github.com/tensorflow/tensor2tensor
---
Photo by Vinh Nguyen on Unsplash

Explore thousands of AI-generated presentations for inspiration
Generate professional presentations in seconds with Karaf's AI. Customize this presentation or start from scratch.
