Slide 1 of 39
Slide 1 - Prezentacja Magisterska
Adaptacyjny Web Scraper z wykorzystaniem modeli językowych
Koncepcja adaptacyjnego systemu ekstrakcji danych z wykorzystaniem AI

Generated from prompt:
prezentację akademicką (seminarium dyplomowe, poziom magisterski) w języku polskim na temat: „Adaptacyjny Web Scraper z wykorzystaniem modeli językowych” 📌 Wymagania ogólne: czas prezentacji: około 10 minut liczba slajdów: 15–18 styl: techniczny, akademicki, zrozumiały każdy slajd: krótki tekst wprowadzający (1 zdanie na górze) 3–5 punktów bulletpoint unikać ścian tekstu stosować czytelne sformułowania prezentacja ma być teoretyczna (bez wyników eksperymentalnych) 🧱 Struktura prezentacji (obowiązkowa): Strona tytułowa Struktura prezentacji Problem badawczy Cel pracy Podstawy web scrapingu Techniki ekstrakcji danych (HTML, API, headless browser) Modele językowe (LLM) Podejścia do wykorzystania LLM Adaptacyjność systemu Architektura systemu Workflow działania Metodologia badań Oczekiwane rezultaty (hipotezy) Zalety i wady podejścia Zastosowania i ograniczenia praktyczne Możliwości rozwoju Podsumowanie Slajd końcowy (pytania) 🧠 Kontekst projektu: projekt dotyczy stworzenia systemu ekstrakcji danych z internetu system ma być adaptacyjny (odporny na zmiany struktury stron) wykorzystuje modele językowe (LLM) jako wsparcie dla klasycznego scrapingu podejście hybrydowe: klasyczny scraping (HTML/API) fallback do LLM 🧪 Zakres analizy: porównanie podejść: klasyczny scraping scraping wspierany przez LLM skupienie na kompromisie: dokładność vs koszt obliczeniowy vs wydajność 📊 Metodologia (do uwzględnienia): testowanie różnych modeli: GPT LLaMA / Mistral metryki: accuracy (poprawność danych) czas przetwarzania koszt (API / lokalne modele) ⚠️ Ważne uwagi: nie zakładaj gotowych wyników eksperymentalnych zamiast tego: przedstaw hipotezy przewidywane rezultaty uwzględnij realne aspekty: API vs HTML scraping anti-bot systems ograniczenia prawne 🎨 Styl slajdów: profesjonalny, minimalistyczny techniczny, ale czytelny sugeruj miejsca na: diagram architektury pipeline danych schemat działania 🎯 Cel prezentacji: Pokazanie koncepcji systemu, uzasadnienie wyboru podejścia oraz przygotowanie gruntu pod przyszłą implementację i badania.
Prezentacja magisterska na temat koncepcji adaptacyjnego systemu ekstrakcji danych z WWW z wykorzystaniem modeli językowych (LLM). Omówienie problemu niestabilności klasycznego scrapingu, architektury hybrydowej, workflow, metodologii badań, zalet, w
Adaptacyjny Web Scraper z wykorzystaniem modeli językowych
Koncepcja adaptacyjnego systemu ekstrakcji danych z wykorzystaniem AI
Adaptacyjny Web Scraper z wykorzystaniem modeli językowych
Seminarium dyplomowe - poziom magisterski
---
Photo by Umberto on Unsplash

Adaptacyjny Web Scraper z wykorzystaniem modeli językowych
Seminarium dyplomowe (poziom magisterski) | Autor: Łukasz Rotko







Analiza klasycznych metod scrapingu i możliwości LLM

Fundamenty techniczne ekstrakcji danych z sieci WWW
---
Photo by Umberto on Unsplash





Koncepcja hybrydowego systemu adaptacyjnego

Wykorzystanie potencjału LLM w inteligentnej ekstrakcji danych
---
Photo by Tom Parkes on Unsplash

---
Photo by Kelly Sikkema on Unsplash


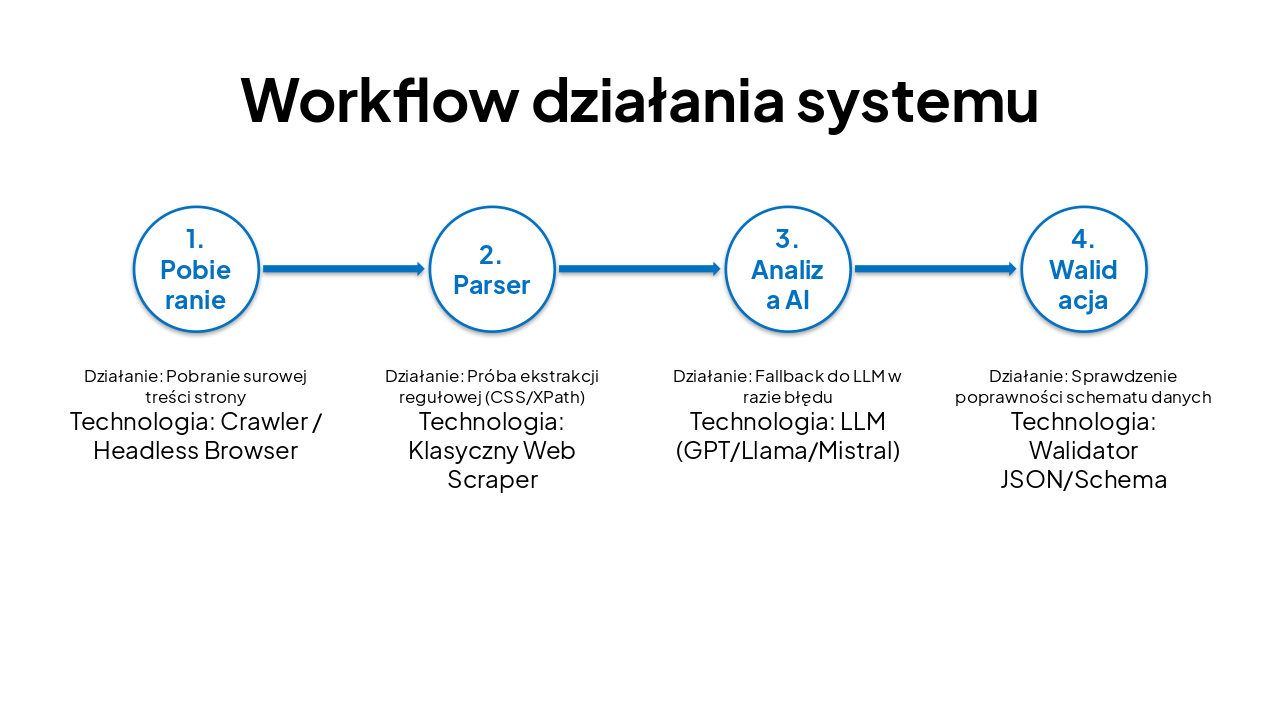
| Krok | Działanie | Technologia |
|---|---|---|
| 1. Pobieranie | Pobranie surowej treści strony | Crawler / Headless Browser |
| 2. Parser | Próba ekstrakcji regułowej (CSS/XPath) | Klasyczny Web Scraper |
| 3. Analiza AI | Fallback do LLM w razie błędu | LLM (GPT/Llama/Mistral) |
| 4. Walidacja | Sprawdzenie poprawności schematu danych | Walidator JSON/Schema |

Teoretyczne ramy badań i hipotezy

Projekt systemu adaptacyjnego oraz plan badań
---
Photo by Tom Parkes on Unsplash





Zalety podejścia LLM
Wady i wyzwania

Zalety podejścia LLM
Wady i ograniczenia

Zalety podejścia LLM
Ograniczenia praktyczne






Dziękuję za uwagę
Dziękuję za uwagę. Czy mają Państwo jakieś pytania?

Podejście hybrydowe stanowi najbardziej efektywne rozwiązanie problemów niestabilności klasycznego web scrapingu.
Podsumowanie koncepcji systemu adaptacyjnego
---
Photo by Nastuh Abootalebi on Unsplash

Podsumowanie: Podejście hybrydowe jest przyszłością ekstrakcji danych.
Dziękuję za uwagę. Czy mają Państwo jakieś pytania?

Dziękuję za uwagę - czy mają Państwo pytania?
Zapraszam do dyskusji

Explore thousands of AI-generated presentations for inspiration
Generate professional presentations in seconds with Karaf's AI. Customize this presentation or start from scratch.